自组织映射(SOM)理论基础与Python NumPy实现
引言
在这份指南中,我们将探讨一种称为自组织映射(SOM)的无监督学习模型,以及其在Python中的实现方法。我们将使用RGB颜色示例来训练SOM,并展示其性能及典型应用。
原文连接:self-organizing-maps-theory-and-implementation-in-python-with-numpy
SOM总体介绍
自组织映射最初由Teuvo Kohonen于1982年引入,有时也被称为Kohonen映射。它是一种特殊类型的人工神经网络,用于构建训练数据的映射。这种映射通常是一个二维的矩形权重网格,但也可以扩展到三维或更高维的模型。其他网格结构,如六角形网格,也是可能的。
SOM主要用于数据可视化,提供一个对训练实例的快速视觉总结。在一个二维矩形网格中,每个单元格由一个权重向量表示。对于一个训练好的SOM,每个单元格的权重代表了一些训练示例的总结。彼此邻近的单元格具有相似的权重,相似的示例可以被映射到彼此相近的小邻域中的单元格。
下图是SOM结构的一个粗略示意图:
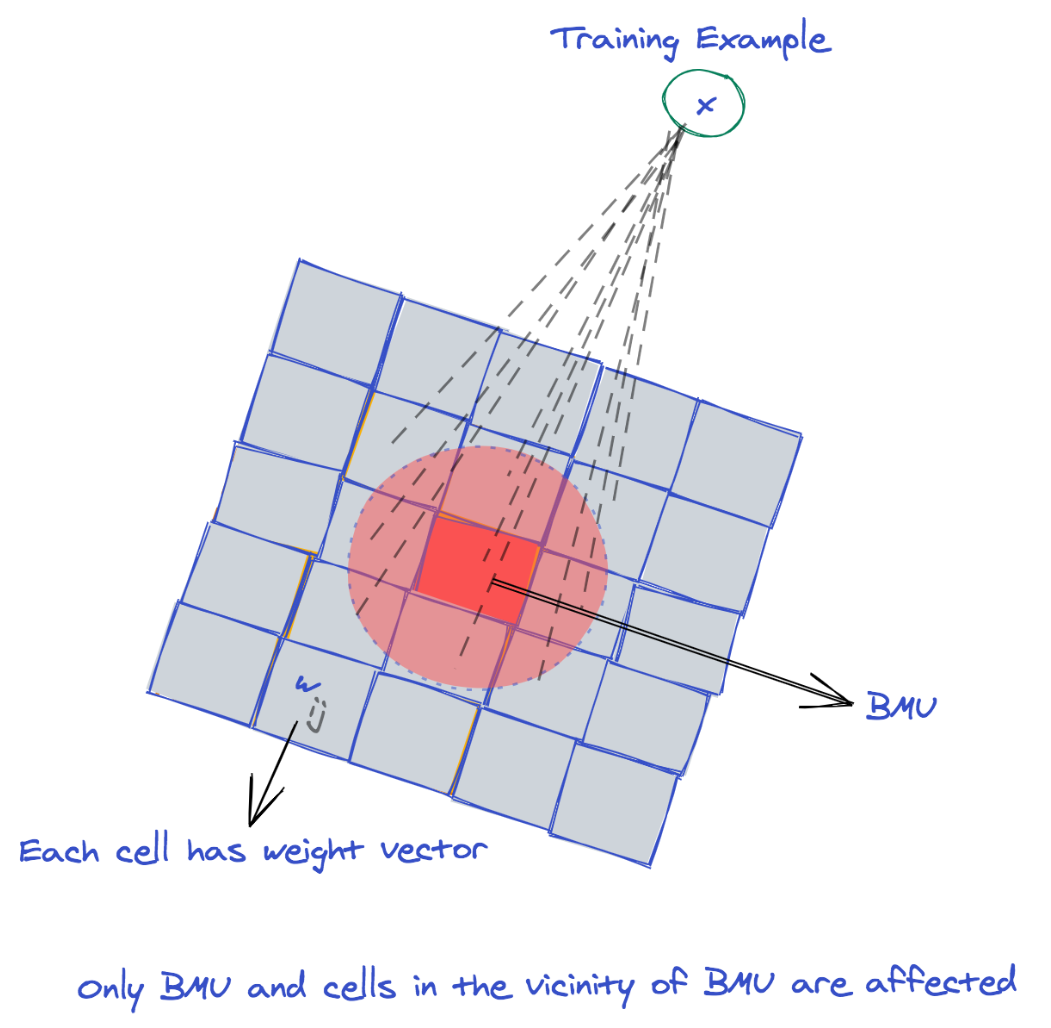
SOM的训练使用了竞争学习。
竞争学习是一种无监督学习的形式,在这种学习中,组成元素相互竞争以产生满意的结果,且只有一个能够赢得竞争。
当一个训练样本被输入到网格中时,将确定最佳匹配单元Best Matching Unit (BMU) ,即竞争的赢家。BMU是其权重最接近训练样本的单元。
接下来,调整BMU的权值和相邻单元的权值,使其更接近输入训练样本。虽然训练和SOM还有其他有效的变体,但我们在本指南中介绍了最流行和广泛使用的SOM实现。
由于我们将使用一些Python例程来演示用于训练SOM的函数,因此让我们导入一些我们将使用的库:
import numpy as np
import matplotlib.pyplot as plt
SOM训练算法
训练SOM的基本算法如下:
初始化SOM的所有网格权重
重复,直到收敛或达到最大的训练轮次(epochs)
打乱训练样本
对于每个训练样本
寻找最佳匹配单元BMU
更新BMU及其相邻单元的权值向量
初始化、查找BMU和更新权重的三个步骤将在以下部分中解释。让我们开始吧!
初始化 SOM 网格
所有SOM网格权值都可以随机初始化。SOM网格权重也可以通过从训练数据集中随机选择的样本来初始化。
你应该选择哪一个?
som对映射的初始权重很敏感,所以这种选择会影响整个模型。根据莱斯特大学和西伯利亚联邦大学的Ayodeji和Evgeny的案例研究:
通过比较相同条件下RI (Random Initialization)优于PCI (Principal Component Initialization)的最终SOM映射的比例,可以观察到RI在非线性数据集上的表现相当好。
然而,对于准线性数据集,结果仍然不确定。总的来说,我们可以得出结论,对于本质上是非线性的数据集,关于PCI优势的假设绝对是错误的。
对于非线性数据集,随机初始化优于非随机初始化。对于准线性数据集,不太清楚哪种方法会始终获胜。给定这些结果-我们将坚持随机初始化。
找到最佳匹配单元(BMU)
如前所述,最佳匹配单元是SOM网格中最接近训练样本的单元,找到BMU的一种方法是计算这个样本与网格中每一个单元的的欧氏距离
距离最小的网格单元可以被选为BMU。
需要注意的是,欧氏距离并不是选择BMU的唯一方法。还可以使用其他距离度量或相似性度量来确定BMU,选择这种度量主要取决于您正在构建的数据和模型。
更新BMU和邻域单元的权重向量
一个训练样本通过拉动一些网格单元的权重向量向样本自身靠近,从而影响SOM网格。影响最大的是BMU,而远离BMU的网格单元影响逐渐减少,直到可以忽略不记。对于坐标的网格单元,它的权重向量在第轮次的更新公式为:
其中 是需要加到上的改变量,计算方式如下:
式中:
- 是当前轮次
- 是BMU的坐标
- 是学习率
- 是半径
- 是邻域函数
接下来的章节,我们将详细展示关于权重训练的表达式
学习率
学习率是一个[0,1]之间的常数,它决定了权重向量向训练样本靠近的步长。如果,表示权重不会发生变化,如果,则权重向量直接被赋值为样本
初始化为一个很大的值,然后随着训练轮次的进行,逐渐减小。一种减小的方式为指数衰减:
其中是衰减率
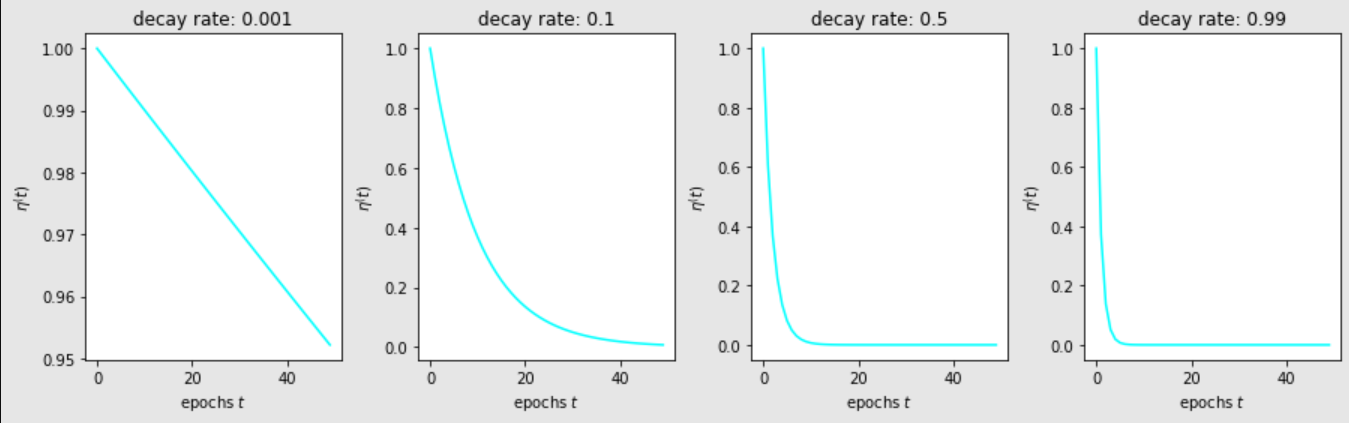
为了理解学习率是如何随衰减率变化的,让我们将初始学习率设置为1时的学习率绘制为不同时期的学习率:
epochs = np.arange(0, 50)
lr_decay = [0.001, 0.1, 0.5, 0.99]
fig,ax = plt.subplots(nrows=1, ncols=4, figsize=(15,4))
plt_ind = np.arange(4) + 141
for decay, ind in zip(lr_decay, plt_ind):
plt.subplot(ind)
learn_rate = np.exp(-epochs * decay)
plt.plot(epochs, learn_rate, c='cyan')
plt.title('decay rate: ' + str(decay))
plt.xlabel('epochs $t$')
plt.ylabel('$\eta^(t)$')
fig.subplots_adjust(hspace=0.5, wspace=0.3)
plt.show()
邻域函数
式中: 是坐标为的单元与坐标为的BMU的距离 是轮次为时的影响半径
通常使用欧氏距离来计算距离,但也可以使用任何其他距离或相似度度量。
由于BMU与自身的距离为零,则BMU的权重变化简化为:
如果一个单元与BMU有一个很大的距离,则邻域函数减少到几乎为0,这会导致一个很小的 所以这样的单元不受训练样本的影响。因此一个训练样本只影响BMU和它周边的单元。影响半径决定了训练样本的影响范围。大的影响半径影响很大网格单元,小的影响半径只影响BMU。通常的策略是一开始使用大的影响半径,然后随着训练轮次,逐渐衰减:
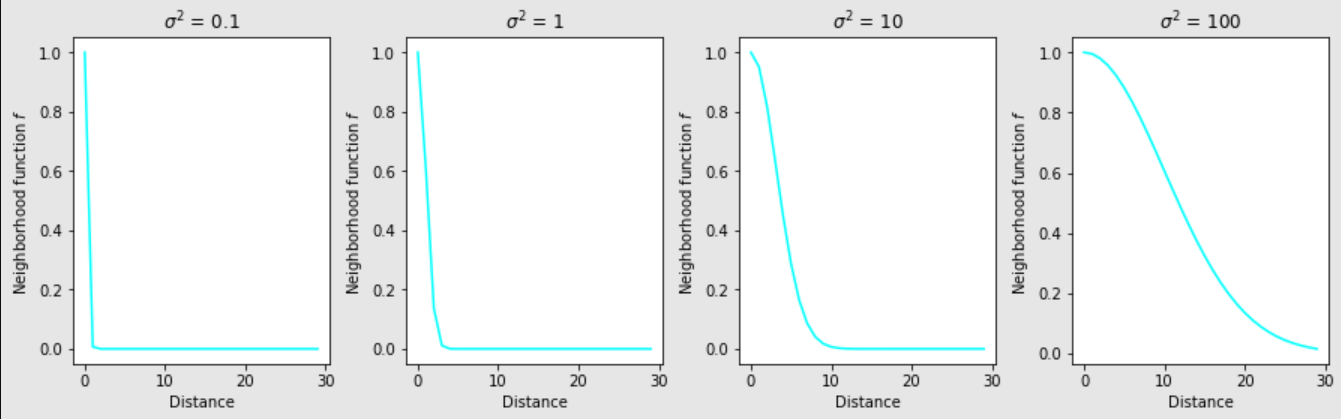
式中: 是衰减速度。半径对应的衰减率和学习率对应的衰减率对影响范围的作用是一样的。为了更深入地了解邻域函数的行为,让我们根据不同半径值的距离绘制它。在这些图中需要注意的一点是,当距离超过10时,距离函数接近于零值
我们将在后面的执行部分使用这个事实来提高训练的效率:
distance = np.arange(0, 30)
sigma_sq = [0.1, 1, 10, 100]
fig,ax = plt.subplots(nrows=1, ncols=4, figsize=(15,4))
plt_ind = np.arange(4) + 141
for s, ind in zip(sigma_sq, plt_ind):
plt.subplot(ind)
f = np.exp(-distance ** 2 / 2 / s)
plt.plot(distance, f, c='cyan')
plt.title('$\sigma^2$ = ' + str(s))
plt.xlabel('Distance')
plt.ylabel('Neighborhood function $f$')
fig.subplots_adjust(hspace=0.5, wspace=0.3)
plt.show()
使用Numpy实现SOM
由于标准机器学习库Scikit-Learn中没有SOM的内置例程,因此我们将使用NumPy手动快速实现。无监督机器学习模型非常简单,易于实现。
我们将SOM实现为2D网格,因此需要3D NumPy数组。第三个维度用于存储每个单元格中的权重(权重向量的元素个数与训练样本的元素个数相同)
# Return the (g,h) index of the BMU in the grid
def find_BMU(SOM,x):
distSq = (np.square(SOM - x)).sum(axis=2)
return np.unravel_index(np.argmin(distSq, axis=None), distSq.shape)
# Update the weights of the SOM cells when given a single training example
# and the model parameters along with BMU coordinates as a tuple
def update_weights(SOM, train_ex, learn_rate, radius_sq,
BMU_coord, step=3):
g, h = BMU_coord
#if radius is close to zero then only BMU is changed
if radius_sq < 1e-3:
SOM[g,h,:] += learn_rate * (train_ex - SOM[g,h,:])
return SOM
# Change all cells in a small neighborhood of BMU
for i in range(max(0, g-step), min(SOM.shape[0], g+step)):
for j in range(max(0, h-step), min(SOM.shape[1], h+step)):
dist_sq = np.square(i - g) + np.square(j - h)
dist_func = np.exp(-dist_sq / 2 / radius_sq)
SOM[i,j,:] += learn_rate * dist_func * (train_ex - SOM[i,j,:])
return SOM
# Main routine for training an SOM. It requires an initialized SOM grid
# or a partially trained grid as parameter
def train_SOM(SOM, train_data, learn_rate = .1, radius_sq = 1,
lr_decay = .1, radius_decay = .1, epochs = 10):
learn_rate_0 = learn_rate
radius_0 = radius_sq
for epoch in np.arange(0, epochs):
rand.shuffle(train_data)
for train_ex in train_data:
g, h = find_BMU(SOM, train_ex)
SOM = update_weights(SOM, train_ex,
learn_rate, radius_sq, (g,h))
# Update learning rate and radius
learn_rate = learn_rate_0 * np.exp(-epoch * lr_decay)
radius_sq = radius_0 * np.exp(-epoch * radius_decay)
return SOM
让我们分解实现自组织映射的关键功能:
当给定SOM网格和一个训练样例x时,find_BMU()返回最佳匹配单元的网格单元坐标。它计算每个单元权重与x之间的欧氏距离的平方,并返回(g,h),即距离最小的单元坐标。
update_weights()函数需要一个SOM网格、一个训练样例x、参数learn_rate和radius_sq、最佳匹配单元的坐标和一个步长参数。理论上,SOM的所有单元都会在下一个训练样本上更新。但是,我们在前面已经说明,对于远离BMU的单元,这种变化可以忽略不计。因此,我们可以通过仅更改BMU附近的一小部分单元格来提高代码的效率。step参数指定在更新权重时要更改的左、右、上、下的最大单元格数。
最后,train_SOM()函数实现了SOM的主要训练过程。它需要初始化或部分训练的SOM网格和train_data作为参数。优点是能够从以前的训练阶段训练SOM。此外,还需要learn_rate和radius_sq参数及其相应的衰减率lr_decay和radius_decay。epochs参数默认设置为10,但可以根据需要进行更改。
在特定样本上运行SOM
训练SOM的一个常用例子是随机颜色。我们可以训练一个SOM网格,并很容易地可视化各种相似的颜色是如何在相邻的单元中排列的。
距离较远的单元颜色不同。
让我们在一个充满随机RGB颜色的训练数据矩阵上运行train_SOM()函数。
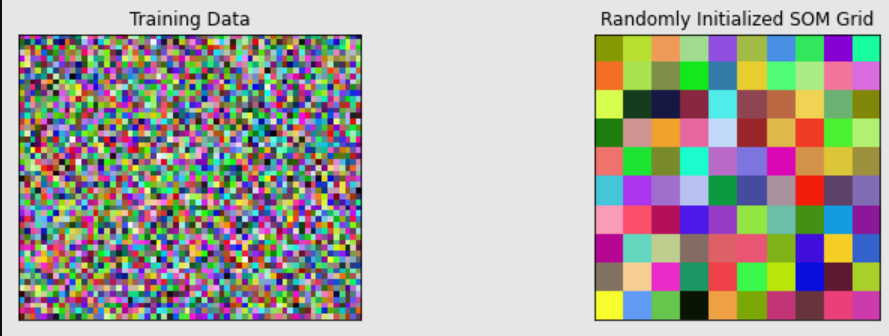
下面的代码初始化了一个训练数据矩阵和一个随机RGB颜色的SOM网格。它还显示训练数据和随机初始化的SOM网格。注意,训练矩阵是一个3000x3的矩阵,但是为了可视化,我们将其重塑为50x60x3的矩阵:
# Dimensions of the SOM grid
m = 10
n = 10
# Number of training examples
n_x = 3000
rand = np.random.RandomState(0)
# Initialize the training data
train_data = rand.randint(0, 255, (n_x, 3))
# Initialize the SOM randomly
SOM = rand.randint(0, 255, (m, n, 3)).astype(float)
# Display both the training matrix and the SOM grid
fig, ax = plt.subplots(
nrows=1, ncols=2, figsize=(12, 3.5),
subplot_kw=dict(xticks=[], yticks=[]))
ax[0].imshow(train_data.reshape(50, 60, 3))
ax[0].title.set_text('Training Data')
ax[1].imshow(SOM.astype(int))
ax[1].title.set_text('Randomly Initialized SOM Grid')
plt.show()
现在让我们训练SOM,并每5轮次检查一次,以快速查看进展:
fig, ax = plt.subplots(
nrows=1, ncols=4, figsize=(15, 3.5),
subplot_kw=dict(xticks=[], yticks=[]))
total_epochs = 0
for epochs, i in zip([1, 4, 5, 10], range(0,4)):
total_epochs += epochs
SOM = train_SOM(SOM, train_data, epochs=epochs)
ax[i].imshow(SOM.astype(int))
ax[i].title.set_text('Epochs = ' + str(total_epochs))

上面的例子非常有趣,因为它展示了网格如何自动排列RGB颜色,以便在SOM网格中相同颜色的各种阴影接近在一起。这种排列早在第一个时期就发生了,但并不理想。我们可以看到,SOM在10个epoch左右收敛,之后的epoch变化较少。
学习率和半径的影响
为了了解不同学习率和半径的学习率是如何变化的,我们可以从相同的初始网格开始运行SOM 10个epoch。下面的代码为三个不同的学习率值和三个不同的半径训练SOM。
SOM在每次模拟5个epoch后渲染:
fig, ax = plt.subplots(
nrows=3, ncols=3, figsize=(15, 15),
subplot_kw=dict(xticks=[], yticks=[]))
# Initialize the SOM randomly to the same state
for learn_rate, i in zip([0.001, 0.5, 0.99], [0, 1, 2]):
for radius_sq, j in zip([0.01, 1, 10], [0, 1, 2]):
rand = np.random.RandomState(0)
SOM = rand.randint(0, 255, (m, n, 3)).astype(float)
SOM = train_SOM(SOM, train_data, epochs = 5,
learn_rate = learn_rate,
radius_sq = radius_sq)
ax[i][j].imshow(SOM.astype(int))
ax[i][j].title.set_text('$\eta$ = ' + str(learn_rate) +
', $\sigma^2$ = ' + str(radius_sq))

上面的示例显示,对于接近于零的半径值(第一列),SOM只更改单个单元格,而不更改相邻的单元格。因此,无论学习率如何,都不会创建合适的映射。对于较小的学习率(第一行,第二列),也会遇到类似的情况。与任何其他机器学习算法一样,理想的训练需要良好的参数平衡。
结论
在本指南中,我们讨论了SOM的理论模型及其详细实现。我们演示了在RGB颜色上的SOM,并展示了相同颜色的不同色调如何在2D网格上组织起来。
虽然som在机器学习社区中不再非常流行,但它们仍然是数据汇总和可视化的良好模型。